PythonのネットワークグラフライブラリのNetworkXと可視化ライブラリのMatplotlibを使うことで、Pythonで簡単に重み付きグラフを可視化できます。具体的なコードとChatGPTとWolframプラグインを利用して作成したサンプルデータを使って、その方法を説明します。
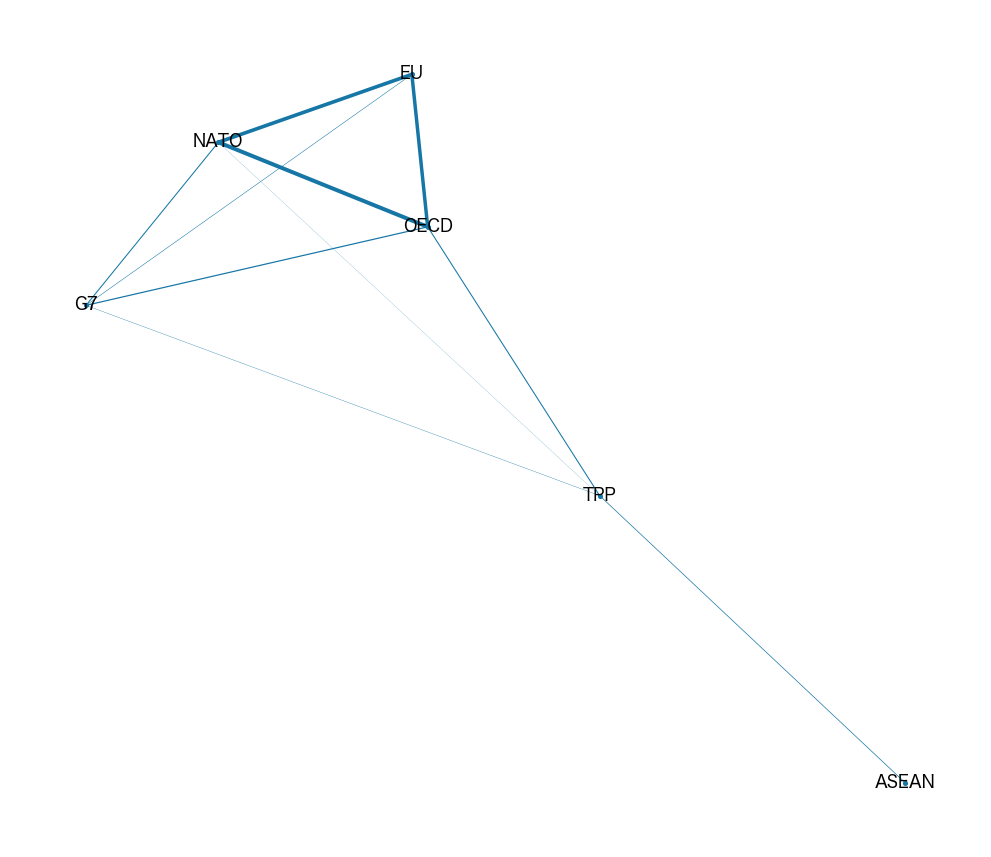
例として国際組織がノード、共通の加盟国がエッジとなっているグラフを考えます。共通する参加国の数をエッジの重みとします。NetworkXとMatplotlibを使うと、以下のようなグラフが作成されます。EU, NATO, OECDは太いエッジで繋がっていることから、共通の加盟国が多いことが見て取れます。
グラフを作成するために、以下のような、国名と参加している国際組織のペアのCSVファイルを用意します。
target_id,label Australia,OECD Austria,OECD Belgium,OECD Canada,OECD Chile,OECD Romania,EU Slovakia,EU Slovenia,EU Spain,EU
次に以下のコードを用意します。実行するとネットワークグラフの画像が作成されます。
import pandas as pd import itertools from collections import defaultdict import networkx as nx import matplotlib.pyplot as plt from typing import List, Dict, Tuple, Union def load_data(file_path: str) -> pd.core.groupby.SeriesGroupBy: # CSVファイルからデータを読み込み、各IDに対応するラベルのリストを作成する。 df = pd.read_csv(file_path) labels_per_id = df.groupby('target_id')['label'].apply(list) return labels_per_id def calculate_edge_weights(labels_per_id: pd.core.groupby.SeriesGroupBy) -> Dict[Tuple[str, str], int]: # 各ラベルペア間で共通のIDの数を計算し、エッジの重みとする。 edge_weights = defaultdict(int) for labels in labels_per_id: for label1, label2 in itertools.combinations(labels, 2): if label1 != label2: edge_weights[(label1, label2)] += 1 return edge_weights def create_network(edge_weights: Dict[Tuple[str, str], int]) -> nx.Graph: # エッジの重みからネットワークを作成する。 G = nx.Graph() for (label1, label2), weight in edge_weights.items(): G.add_edge(label1, label2, weight=weight) return G def set_edge_weights(G: nx.Graph, weight_devisor: int = 2) -> List[float]: # エッジの太さを設定する。エッジの重みを調整するパラメータとして weight_devisor を使用する。 weights = [G[u][v]['weight']/weight_devisor for u,v in G.edges()] return weights def compute_layout(G: nx.Graph, k: Union[int, float] = 1) -> Dict[str, Tuple[float, float]]: # ネットワークのレイアウトを計算する。ノード間の間隔を調整するパラメータとして k を使用する。 pos = nx.spring_layout(G, k=k) return pos def draw_network(G: nx.Graph, pos: Dict[str, Tuple[float, float]], weights: List[float], font_families: List[str] = ['Hiragino Sans', 'Osaka']) -> None: # ネットワークを描画する。エッジの太さやフォントなどの設定もここで行う。 nx.draw(G, with_labels=True, width=weights, font_family=font_families, node_size=7, pos=pos, node_color='#1676a6', edge_color='#1676a6') plt.show() def main() -> None: # 上記の関数を組み合わせて全体のプロセスを実行する。 labels_per_id = load_data('data5.csv') edge_weights = calculate_edge_weights(labels_per_id) G = create_network(edge_weights) weights = set_edge_weights(G, 8) pos = compute_layout(G) draw_network(G, pos, weights) if __name__ == '__main__': main() print("done")
日本語のラベルを表示するには、nx.drawにfont_familyを指定する必要があります。上記のコードはmacOS用なので、ヒラギノが指定されています。必要に応じて実行環境にインストールされているフォントを指定してください。
ちなみにこのサンプルデータはChatGPTとWolframプラグインを使って作成しました。ChatGPTは指定したフォーマットで出力するのも得意なので、こういう仕事を頼むと便利です。
